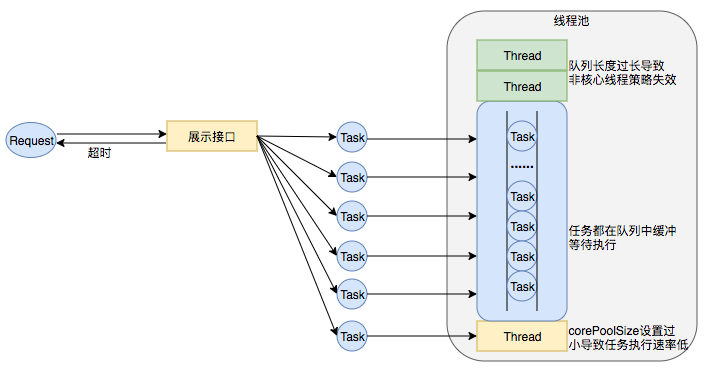
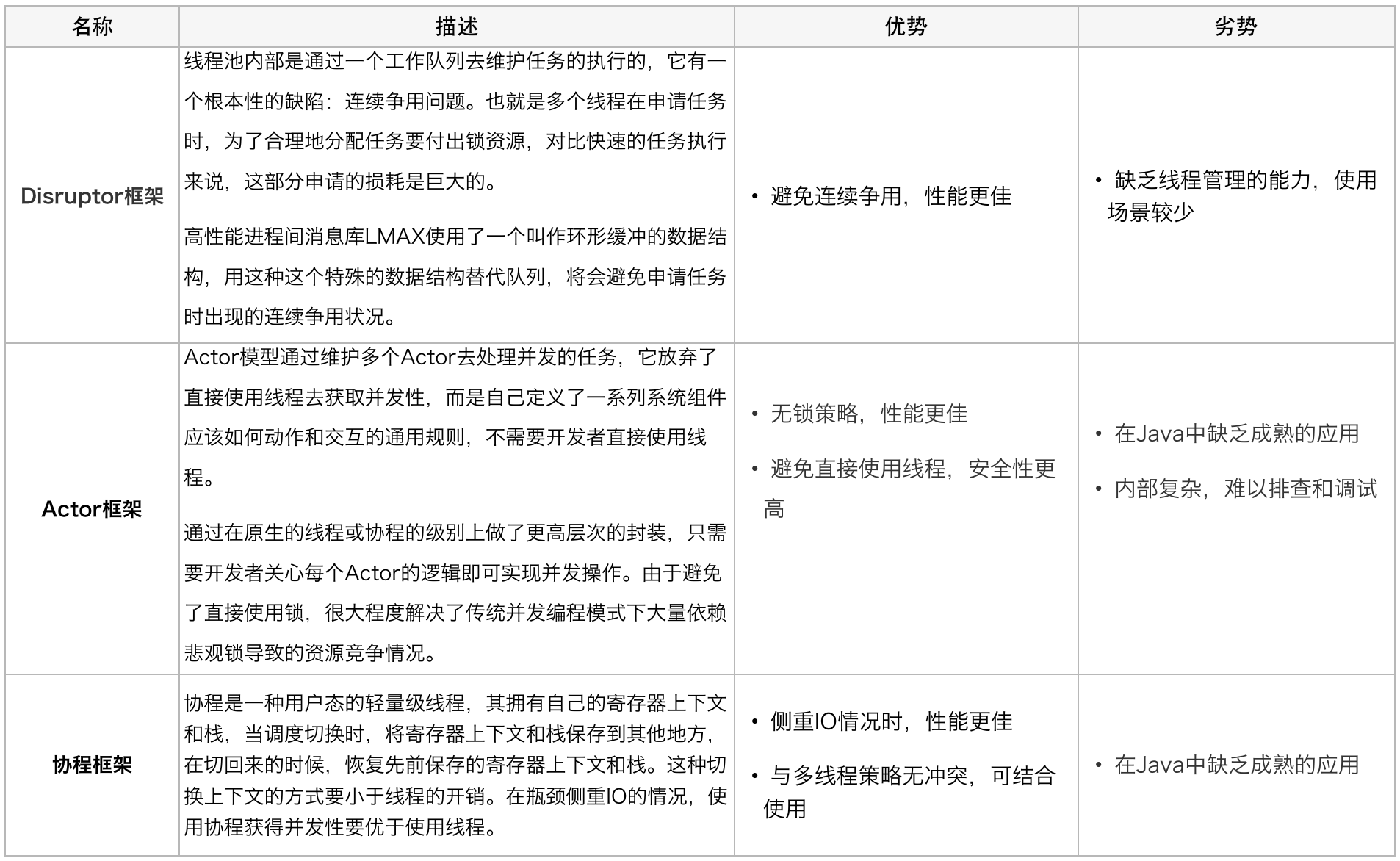
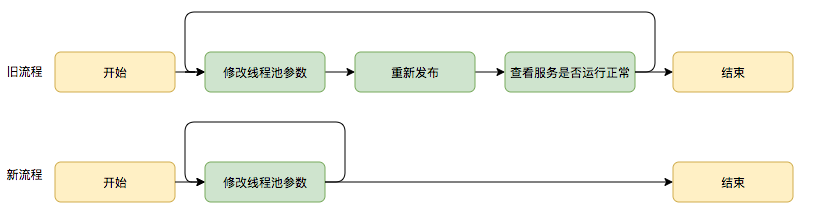
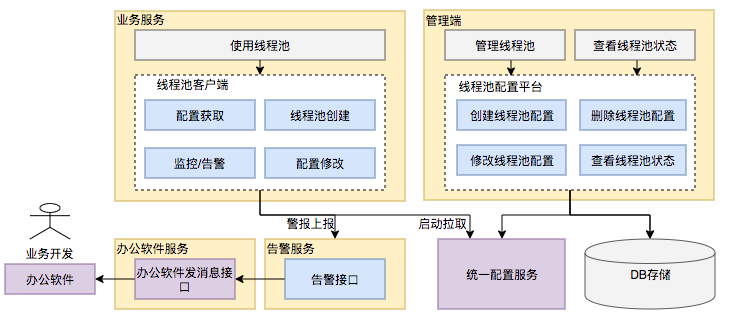
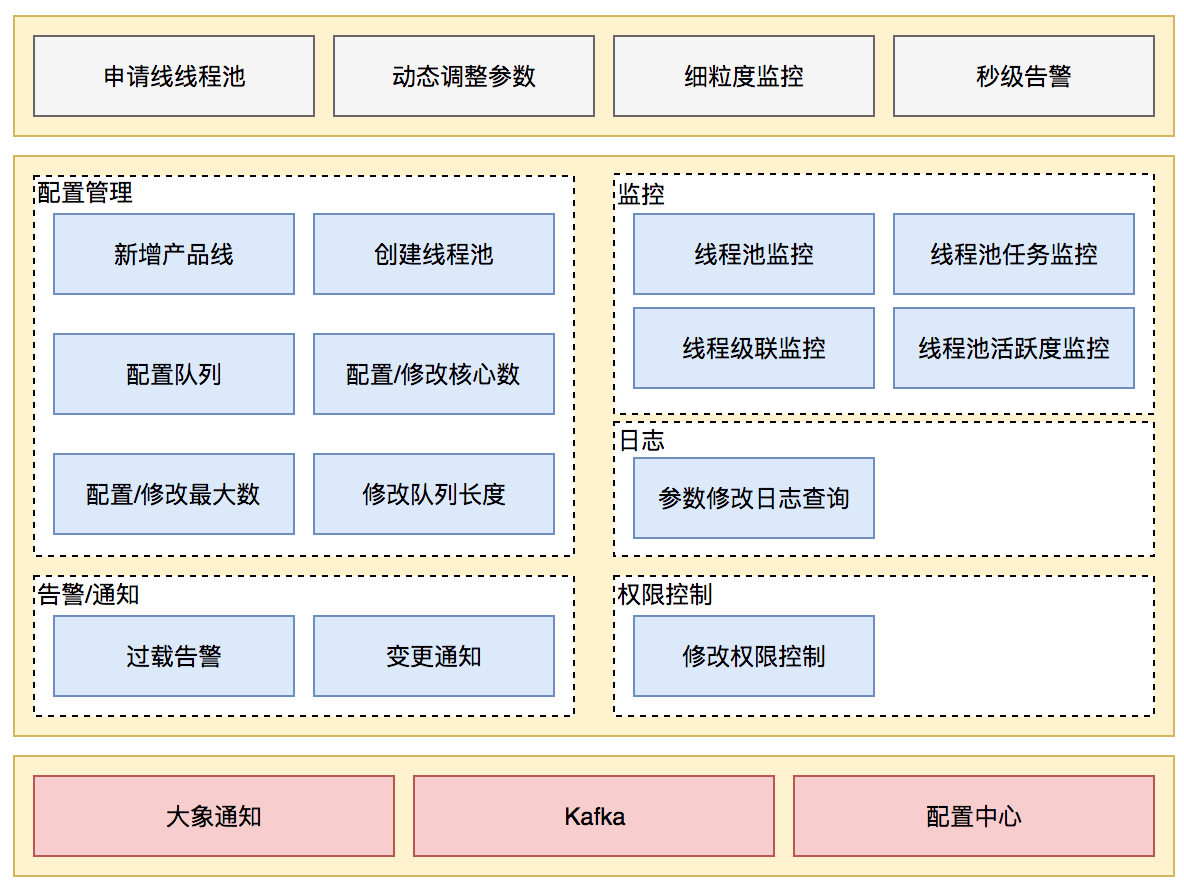
前言
最近正在啃《高性能MySQL》这本书, 当看到事务相关知识时,决定对该知识点稍微深入一下, 《高性能MySQL》中在介绍事务相关知识点时, 显然不是特别深入, 很多比较底层的知识点并没有太多的深入, 当然此处并不是要对本书做什么评判,言归正传, 这里主要先说一下本人在啃相关知识点时的曲折之路:
- 首先是事务相关ACID特性, 之前已经有相关笔记进行过介绍, 这里不再重复;
- 接下来是高并发事务相关的问题, 像是
脏读,不可重复读,幻读,更新丢失等问题之前也有相关笔记; - 再下来就是MySQL应对高并发事务是如何给出解决方案的(其中包含各个隔离级别的简介);
- 然后就是各个隔离级别的具体介绍及与锁的关系, 也就是在这部分知识点, 发现了之前并没有过多关心的知识点
MVCC多版本并发控制, 然后一发不可收拾了…
入题
下面先引用一些前辈们比较优秀的文章:
阿里数据库内核’2017/12’月报中对MVCC的解释是:
多版本控制: 指的是一种提高并发的技术。最早的数据库系统,只有读读之间可以并发,读写,写读,写写都要阻塞。引入多版本之后,只有写写之间相互阻塞,其他三种操作都可以并行,这样大幅度提高了InnoDB的并发度。在内部实现中,与Postgres在数据行上实现多版本不同,InnoDB是在undolog中实现的,通过undolog可以找回数据的历史版本。找回的数据历史版本可以提供给用户读(按照隔离级别的定义,有些读请求只能看到比较老的数据版本),也可以在回滚的时候覆盖数据页上的数据。在InnoDB内部中,会记录一个全局的活跃读写事务数组,其主要用来判断事务的可见性。
<高性能MySQL>中对MVCC的部分介绍
MySQL的大多数事务型存储引擎实现的其实都不是简单的行级锁。基于提升并发性能的考虑, 它们一般都同时实现了多版本并发控制(MVCC)。不仅是MySQL, 包括Oracle,PostgreSQL等其他数据库系统也都实现了MVCC, 但各自的实现机制不尽相同, 因为MVCC没有一个统一的实现标准。
可以认为MVCC是行级锁的一个变种, 但是它在很多情况下避免了加锁操作, 因此开销更低。虽然实现机制有所不同, 但大都实现了非阻塞的读操作,写操作也只锁定必要的行。
MVCC的实现方式有多种, 典型的有乐观(optimistic)并发控制 和 悲观(pessimistic)并发控制。
MVCC只在 READ COMMITTED 和 REPEATABLE READ 两个隔离级别下工作。其他两个隔离级别够和MVCC不兼容, 因为 READ UNCOMMITTED 总是读取最新的数据行, 而不是符合当前事务版本的数据行。而 SERIALIZABLE 则会对所有读取的行都加锁。
从书中可以了解到:
- MVCC是被Mysql中 事务型存储引擎InnoDB 所支持的;
- 应对高并发事务, MVCC比单纯的加锁更高效;
- MVCC只在 READ COMMITTED 和 REPEATABLE READ 两个隔离级别下工作;
- MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;
- 各数据库中MVCC实现并不统一
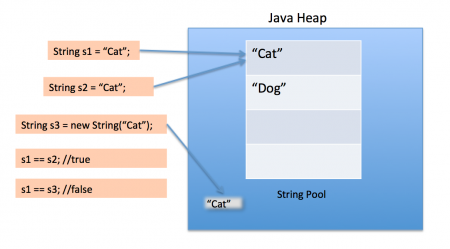
- 但是书中提到 “InnoDB的MVCC是通过在每行记录后面保存两个隐藏的列来实现的”(网上也有很多此类观点), 但其实并不准确, 可以参考MySQL官方文档, 可以看到, InnoDB存储引擎在数据库每行数据的后面添加了三个字段, 不是两个!!
相关概念
1.read view, 快照snapshot
淘宝数据库内核月报/2017/10/01/
此文虽然是以PostgreSQL进行的说明, 但并不影响理解, 在”事务快照的实现”该部分有细节需要注意:
事务快照是用来存储数据库的事务运行情况。一个事务快照的创建过程可以概括为:
查看当前所有的未提交并活跃的事务,存储在数组中
选取未提交并活跃的事务中最小的XID,记录在快照的xmin中
选取所有已提交事务中最大的XID,加1后记录在xmax中
注意: 上文中在PostgreSQL中snapshot的概念, 对应MySQL中, 其实就是你在网上看到的read view,快照这些概念;
比如何登成就有关于Read view的介绍;
而 此文 却仍是使用快照来介绍;
2.read view 主要是用来做可见性判断的, 比较普遍的解释便是”本事务不可见的当前其他活跃事务”, 但正是该解释, 可能会造成一节理解上的误区, 所以此处提供两个参考, 供给大家避开理解误区:
1 | read view中的`高水位low_limit_id`可以参考 https://github.com/zhangyachen/zhangyachen.github.io/issues/68, https://www.zhihu.com/question/66320138其实上面第1点中加粗部分也是相关高水位的介绍( 注意进行了+1 ) |
3.另外, 对于read view快照的生成时机, 也非常关键, 正是因为生成时机的不同, 造成了RC,RR两种隔离级别的不同可见性;
在innodb中(默认repeatable read级别), 事务在begin/start transaction之后的第一条select读操作后, 会创建一个快照(read view), 将当前系统中活跃的其他事务记录记录起来;
在innodb中(默认repeatable committed级别), 事务中每条select语句都会创建一个快照(read view);
参考
1 | With REPEATABLE READ isolation level, the snapshot is based on the time when the first read operation is performed. |
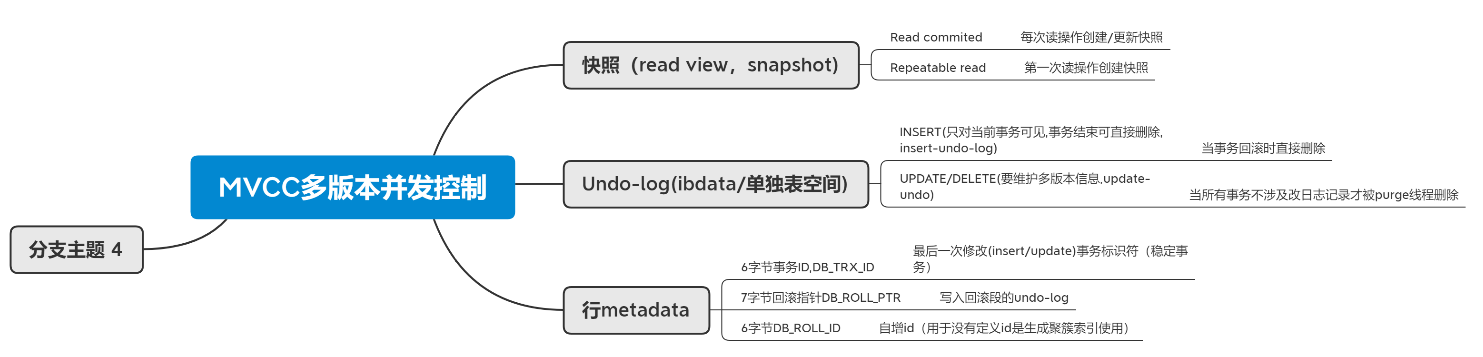
4.undo-log
Undo log是InnoDB MVCC事务特性的重要组成部分。当我们对记录做了变更操作时就会产生undo记录,Undo记录默认被记录到系统表空间(ibdata)中,但从5.6开始,也可以使用独立的Undo 表空间。
Undo记录中存储的是老版本数据,当一个旧的事务需要读取数据时,为了能读取到老版本的数据,需要顺着undo链找到满足其可见性的记录。当版本链很长时,通常可以认为这是个比较耗时的操作(例如bug#69812)。
大多数对数据的变更操作包括INSERT/DELETE/UPDATE,其中INSERT操作在事务提交前只对当前事务可见,因此产生的Undo日志可以在事务提交后直接删除(谁会对刚插入的数据有可见性需求呢!!),而对于UPDATE/DELETE则需要维护多版本信息,在InnoDB里,UPDATE和DELETE操作产生的Undo日志被归成一类,即update_undo
另外, 在回滚段中的undo logs分为: insert undo log 和 update undo loginsert undo log : 事务对insert新记录时产生的undolog, 只在事务回滚时需要, 并且在事务提交后就可以立即丢弃。
update undo log : 事务对记录进行delete和update操作时产生的undo log, 不仅在事务回滚时需要, 一致性读也需要,所以不能随便删除,只有当数据库所使用的快照中不涉及该日志记录,对应的回滚日志才会被purge线程删除。
5.InnoDB存储引擎在数据库每行数据的后面添加了三个字段
- 6字节的事务ID(DB_TRX_ID)字段: 用来标识最近一次对本行记录做修改(insert|update)的事务的标识符, 即最后一次修改(insert|update)本行记录的事务id。
- 至于delete操作,在innodb看来也不过是一次update操作,更新行中的一个特殊位将行表示为deleted, 并非真正删除。
- 7字节的回滚指针(DB_ROLL_PTR)字段: 指写入回滚段(rollback segment)的 undo log record (撤销日志记录记录)。
- 如果一行记录被更新, 则 undo log record 包含 ‘重建该行记录被更新之前内容’ 所必须的信息。
- 6字节的DB_ROW_ID字段: 包含一个随着新行插入而单调递增的行ID, 当由innodb自动产生聚集索引时,聚集索引会包括这个行ID的值,否则这个行ID不会出现在任何索引中。
- 结合聚簇索引的相关知识点, 我的理解是, 如果我们的表中没有主键或合适的唯一索引, 也就是无法生成聚簇索引的时候, InnoDB会帮我们自动生成聚集索引, 但聚簇索引会使用DB_ROW_ID的值来作为主键; 如果我们有自己的主键或者合适的唯一索引, 那么聚簇索引中也就不会包含 DB_ROW_ID 了 。
- 关于聚簇索引, 《高性能MySQL》中的篇幅对我来说已经够用了, 稍后会整理一下以前的学习笔记, 然后更新上来。
6.可见性比较算法(这里每个比较算法后面的描述是建立在rr级别下,rc级别也是使用该比较算法,此处未做描述)
设要读取的行的最后提交事务id(即当前数据行的稳定事务id)为 trx_id_current
当前新开事务id为 new_id
当前新开事务创建的快照read view 中最早的事务id为up_limit_id, 最迟的事务id为low_limit_id(注意这个low_limit_id=未开启的事务id=当前最大事务id+1)
比较:
- 1.trx_id_current < up_limit_id, 这种情况比较好理解, 表示, 新事务在读取该行记录时, 该行记录的稳定事务ID是小于, 系统当前所有活跃的事务, 所以当前行稳定数据对新事务可见, 跳到步骤5.
- 2.trx_id_current >= trx_id_last, 这种情况也比较好理解, 表示, 该行记录的稳定事务id是在本次新事务创建之后才开启的, 但是却在本次新事务执行第二个select前就commit了,所以该行记录的当前值不可见, 跳到步骤4。
- 3.trx_id_current <= trx_id_current <= trx_id_last, 表示: 该行记录所在事务在本次新事务创建的时候处于活动状态,从up_limit_id到low_limit_id进行遍历,如果trx_id_current等于他们之中的某个事务id的话,那么不可见, 调到步骤4,否则表示可见。
- 4.从该行记录的 DB_ROLL_PTR 指针所指向的回滚段中取出最新的undo-log的版本号, 将它赋值该 trx_id_current,然后跳到步骤1重新开始判断。
- 5.将该可见行的值返回。
案例分析
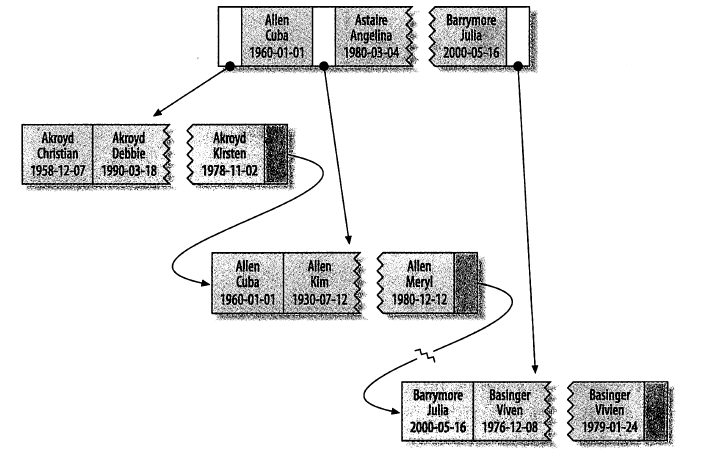
下面是一个非常简版的演示事务对某行记录的更新过程, 当然, InnoDB引擎在内部要做的工作非常多:

下面是一套比较算法的应用过程, 比较长

当前读和快照读
1.MySQL的InnoDB存储引擎默认事务隔离级别是RR(可重复读), 是通过 “行排他锁+MVCC” 一起实现的, 不仅可以保证可重复读, 还可以部分防止幻读, 而非完全防止;
2.为什么是部分防止幻读, 而不是完全防止?
效果: 在如果事务B在事务A执行中, insert了一条数据并提交, 事务A再次查询, 虽然读取的是undo中的旧版本数据(防止了部分幻读), 但是事务A中执行update或者delete都是可以成功的!!
因为在innodb中的操作可以分为当前读(current read)和快照读(snapshot read):
3.快照读(snapshot read)
1 | 简单的select操作(当然不包括 select ... lock in share mode, select ... for update) |
4.当前读(current read) 官网文档 Locking Reads
select … lock in share mode
select … for update
insert
update
delete
在RR级别下,快照读是通过MVVC(多版本控制)和undo log来实现的,当前读是通过加record lock(记录锁)和gap lock(间隙锁)来实现的。
innodb在快照读的情况下并没有真正的避免幻读, 但是在当前读的情况下避免了不可重复读和幻读!!!
小结
- 一般我们认为MVCC有下面几个特点:
每行数据都存在一个版本,每次数据更新时都更新该版本
修改时Copy出当前版本, 然后随意修改,各个事务之间无干扰
保存时比较版本号,如果成功(commit),则覆盖原记录, 失败则放弃copy(rollback)
就是每行都有版本号,保存时根据版本号决定是否成功,听起来含有乐观锁的味道, 因为这看起来正是,在提交的时候才能知道到底能否提交成功
- 而InnoDB实现MVCC的方式是:
- 事务以排他锁的形式修改原始数据
- 把修改前的数据存放于undo log,通过回滚指针与主数据关联
- 修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
- 二者最本质的区别是: 当修改数据时是否要排他锁定,如果锁定了还算不算是MVCC?
- Innodb的实现真算不上MVCC, 因为并没有实现核心的多版本共存, undo log 中的内容只是串行化的结果, 记录了多个事务的过程, 不属于多版本共存。但理想的MVCC是难以实现的, 当事务仅修改一行记录使用理想的MVCC模式是没有问题的, 可以通过比较版本号进行回滚, 但当事务影响到多行数据时, 理想的MVCC就无能为力了。
- 比如, 如果事务A执行理想的MVCC, 修改Row1成功, 而修改Row2失败, 此时需要回滚Row1, 但因为Row1没有被锁定, 其数据可能又被事务B所修改, 如果此时回滚Row1的内容,则会破坏事务B的修改结果,导致事务B违反ACID。 这也正是所谓的 第一类更新丢失 的情况。
- 也正是因为InnoDB使用的MVCC中结合了排他锁, 不是纯的MVCC, 所以第一类更新丢失是不会出现了, 一般说更新丢失都是指第二类丢失更新。