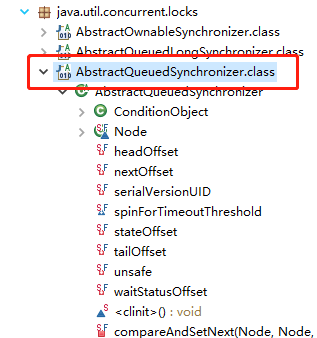
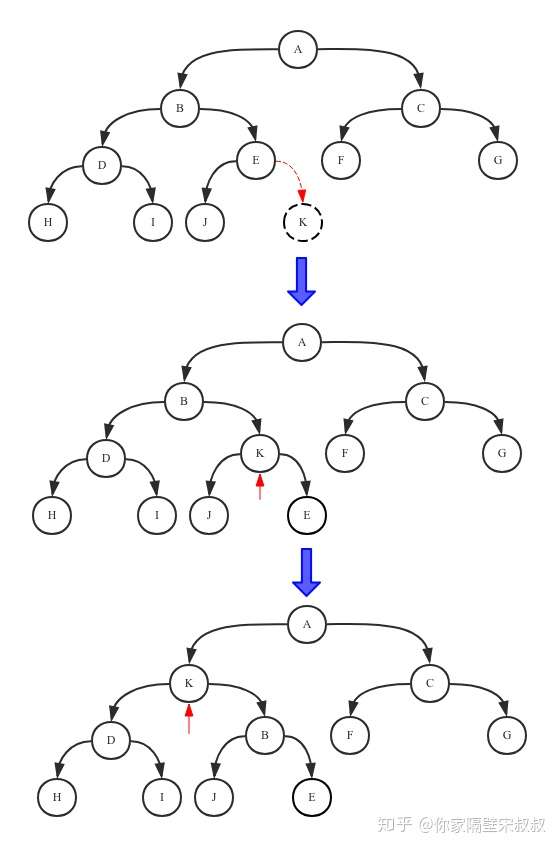
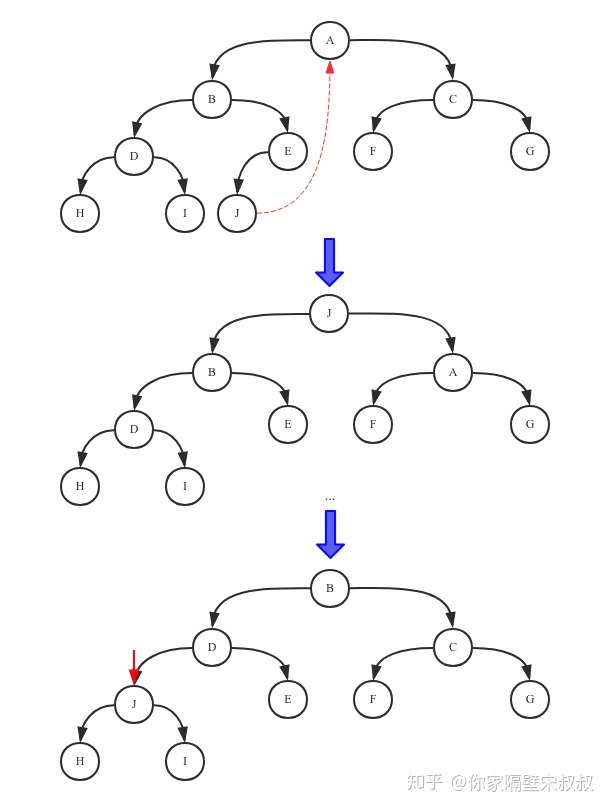
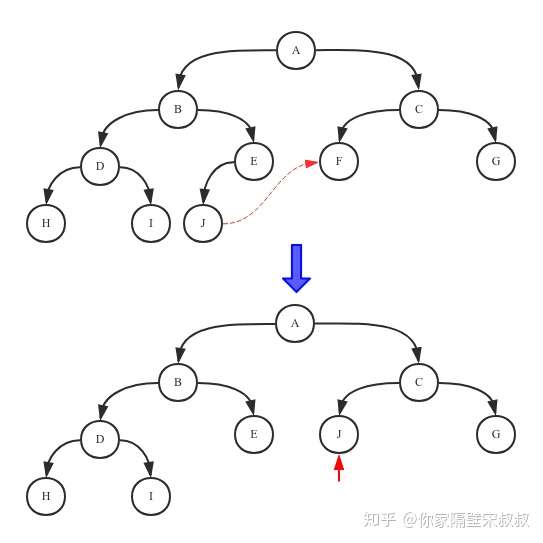
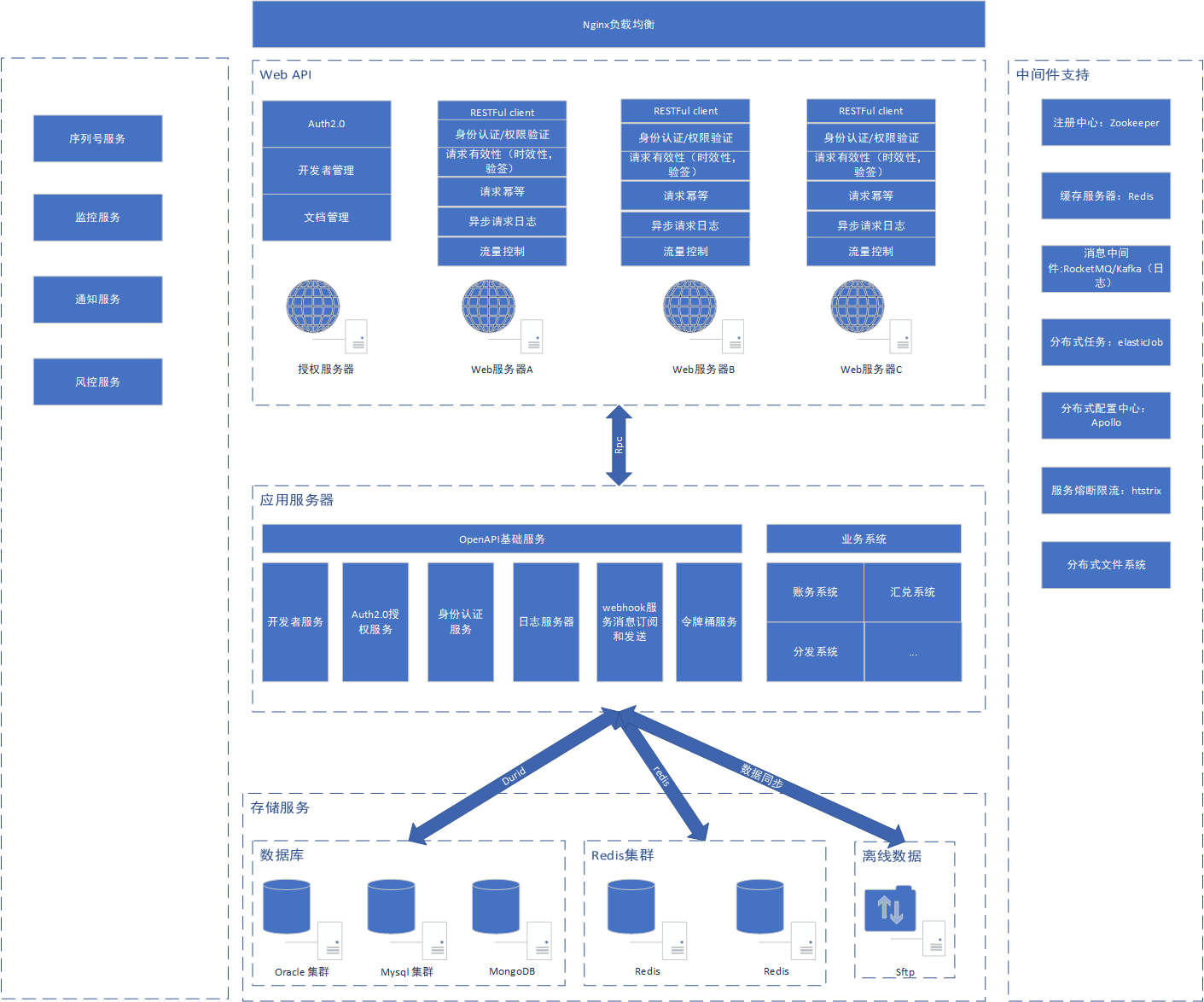
默认情况下,每个方法都抛出 UnsupportedOperationException。 这些方法的实现必须是内部线程安全的,并且通常应该简短而不是阻塞。AQS 类中的其他方法都是 final ,所以无法被其他类使用,只有这几个方法可以被其他类使用。
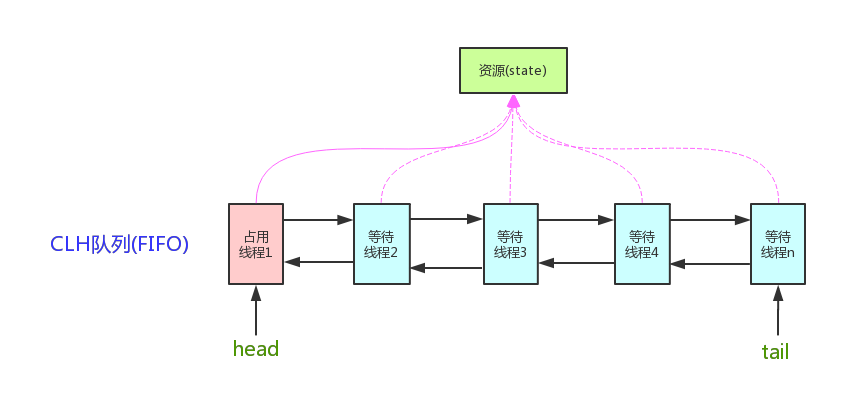
以 ReentrantLock 为例,state 初始化为 0,表示未锁定状态。A 线程 lock()时,会调用 tryAcquire()独占该锁并将 state+1。此后,其他线程再 tryAcquire()时就会失败,直到 A 线程 unlock()到 state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证 state 是能回到零态的。
再以 CountDownLatch 以例,任务分为 N 个子线程去执行,state 也初始化为 N(注意 N 要与线程个数一致)。这 N 个子线程是并行执行的,每个子线程执行完后 countDown()一次,state 会 CAS(Compare and Swap)减 1。等到所有子线程都执行完后(即 state=0),会 unpark()主调用线程,然后主调用线程就会从 await()函数返回,继续后余动作。
// 当线程数量或者请求数量达到 count 时 await 之后的方法才会被执行。上面的示例中 count 的值就为 5。 privateint count; /** * Main barrier code, covering the various policies. */ privateintdowait(boolean timed, long nanos) throws InterruptedException, BrokenBarrierException, TimeoutException { final ReentrantLock lock = this.lock; // 锁住 lock.lock(); try { final Generation g = generation;
if (g.broken) thrownew BrokenBarrierException();
// 如果线程中断了,抛出异常 if (Thread.interrupted()) { breakBarrier(); thrownew InterruptedException(); } // cout减1 int index = --count; // 当 count 数量减为 0 之后说明最后一个线程已经到达栅栏了,也就是达到了可以执行await 方法之后的条件 if (index == 0) { // tripped boolean ranAction = false; try { final Runnable command = barrierCommand; if (command != null) command.run(); ranAction = true; // 将 count 重置为 parties 属性的初始化值 // 唤醒之前等待的线程 // 下一波执行开始 nextGeneration(); return0; } finally { if (!ranAction) breakBarrier(); } }
// loop until tripped, broken, interrupted, or timed out for (;;) { try { if (!timed) trip.await(); elseif (nanos > 0L) nanos = trip.awaitNanos(nanos); } catch (InterruptedException ie) { if (g == generation && ! g.broken) { breakBarrier(); throw ie; } else { // We're about to finish waiting even if we had not // been interrupted, so this interrupt is deemed to // "belong" to subsequent execution. Thread.currentThread().interrupt(); } }
CountDownLatch: A synchronization aid that allows one or more threads to wait until a set of operations being performed in other threads completes.(CountDownLatch: 一个或者多个线程,等待其他多个线程完成某件事情之后才能执行;) CyclicBarrier : A synchronization aid that allows a set of threads to all wait for each other to reach a common barrier point.(CyclicBarrier : 多个线程互相等待,直到到达同一个同步点,再继续一起执行。)
对于 CountDownLatch 来说,重点是“一个线程(多个线程)等待”,而其他的 N 个线程在完成“某件事情”之后,可以终止,也可以等待。而对于 CyclicBarrier,重点是多个线程,在任意一个线程没有完成,所有的线程都必须等待。
A buffer’s position is the index of the next element to be read or written. A buffer’s position is never negative and is never greater than its limit. 当前操作的位置
private int limit;
A buffer’s limit is the index of the first element that should not be read or written. A buffer’s limit is never negative and is never greater than its capacity. 可以存放的元素的个数
private int capacity;
A buffer’s capacity is the number of elements it contains. The capacity of a buffer is never negative and never changes. 数组容量
/** * Create a {@code ReduceOp} of the specified stream shape which uses * the specified {@code Supplier} to create accumulating sinks. * * @param shape The shape of the stream pipeline */ ReduceOp(StreamShape shape) { inputShape = shape; }
publicabstract S makeSink();
@Override public StreamShape inputShape(){ return inputShape; }
@Override public <P_IN> R evaluateSequential(PipelineHelper<T> helper, Spliterator<P_IN> spliterator){ return helper.wrapAndCopyInto(makeSink(), spliterator).get(); }
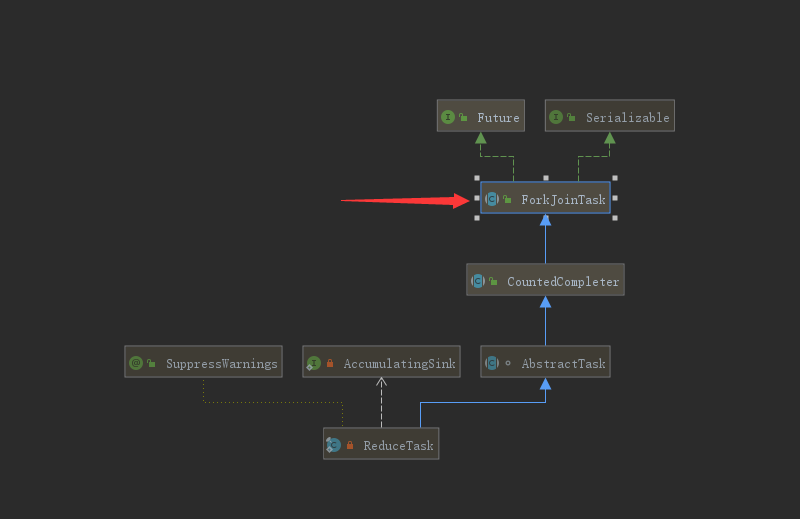
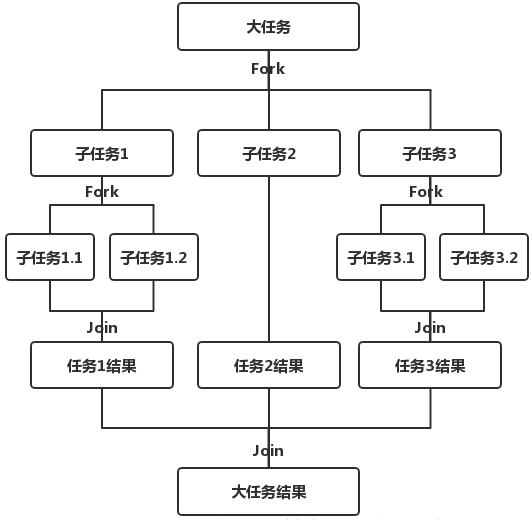
@Override public <P_IN> R evaluateParallel(PipelineHelper<T> helper, Spliterator<P_IN> spliterator){ // 这里new出了一个 ReduceTask returnnew ReduceTask<>(this, helper, spliterator).invoke().get(); } }
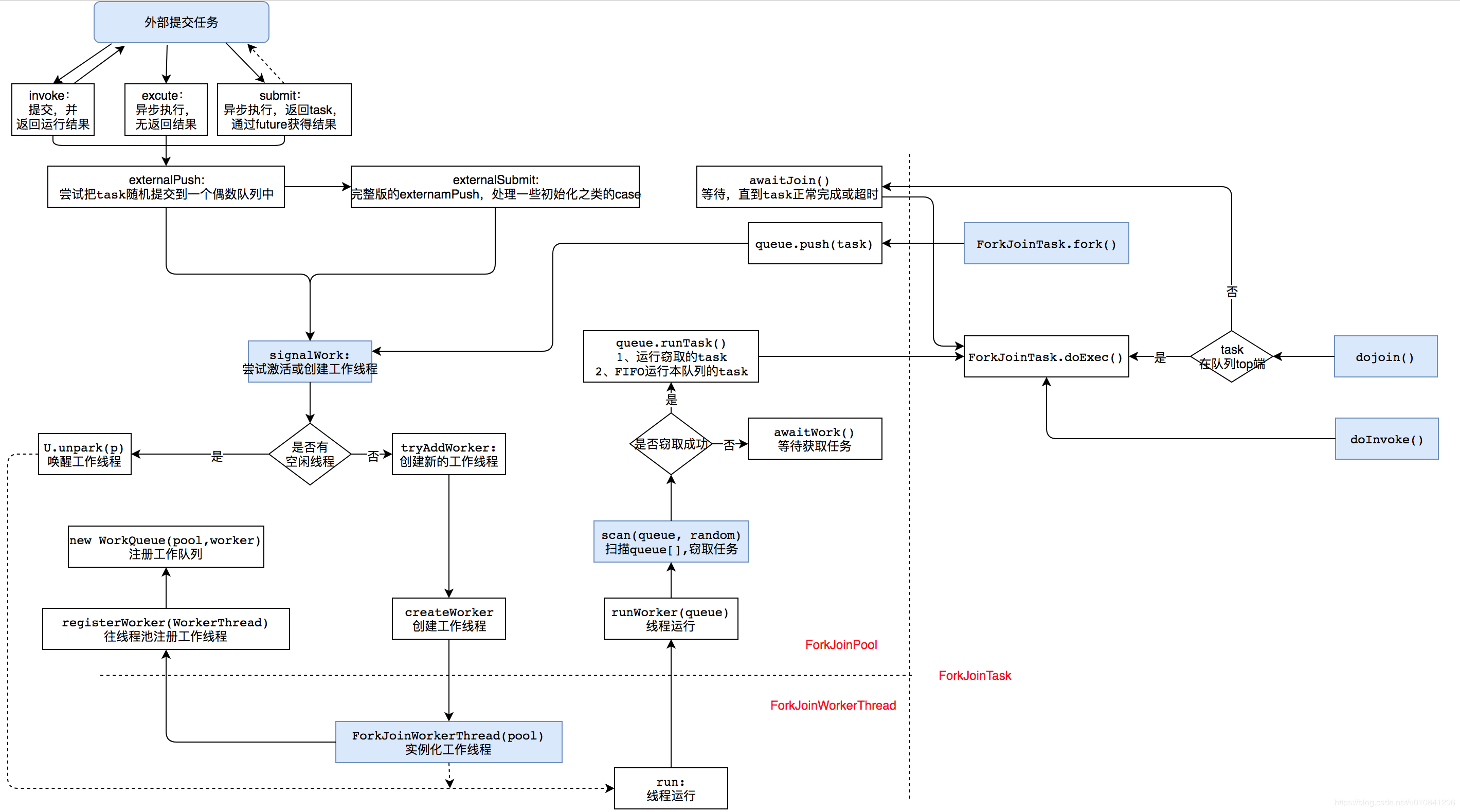
publicstaticinterfaceForkJoinWorkerThreadFactory{ /** * Returns a new worker thread operating in the given pool. * * @param pool the pool this thread works in * @return the new worker thread * @throws NullPointerException if the pool is null */ public ForkJoinWorkerThread newThread(ForkJoinPool pool); }
1 2 3 4 5 6 7 8 9 10 11
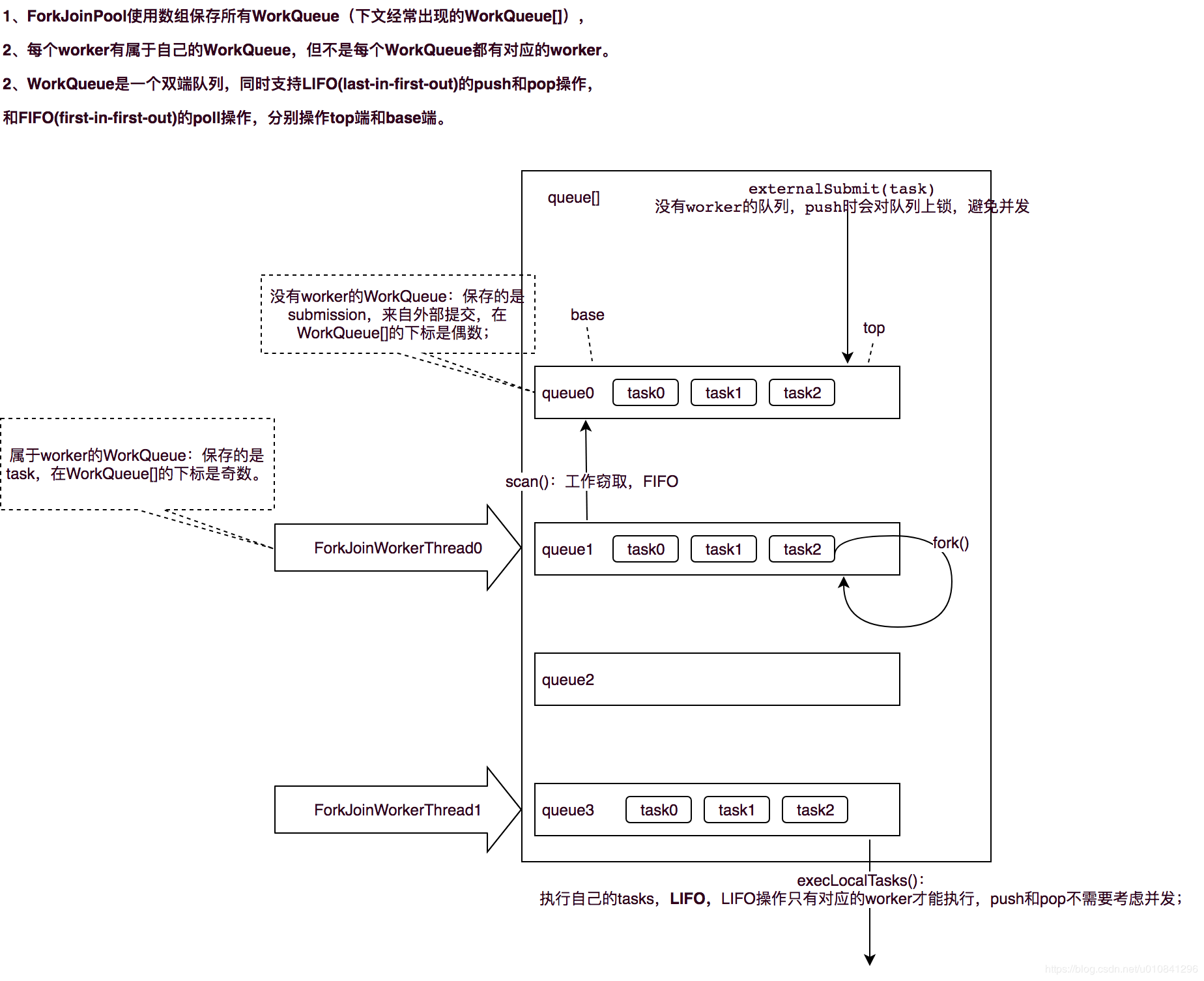
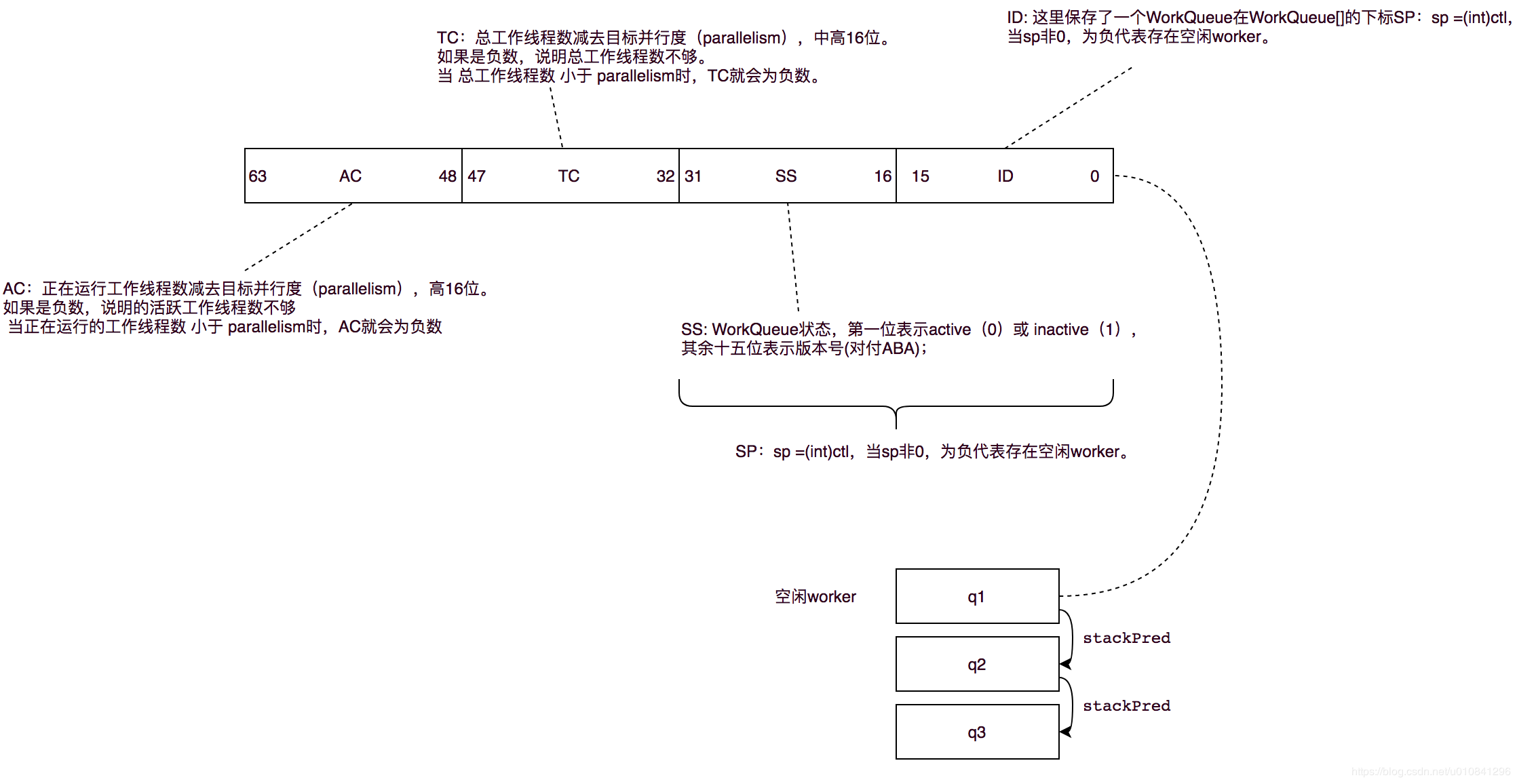
// Instance fields volatileint scanState; // 负数:inactive, 非负数:active, 其中奇数代表scanning int stackPred; // sp = (int)ctl, 前一个队列栈的标示信息,包含版本号、是否激活、以及队列索引 int nsteals; // 窃取的任务数 int hint; // 一个随机数,用来帮助任务窃取,在 helpXXXX()的方法中会用到 int config; // 配置:二进制的低16位代表 在 queue[] 中的索引, // 高16位:mode可选FIFO_QUEUE(1 << 16)和LIFO_QUEUE(1 << 31),默认是LIFO_QUEUE volatileint qlock; // 锁定标示位:1: locked, < 0: terminate; else 0 volatileint base; // index of next slot for poll int top; // index of next slot for push ForkJoinTask<?>[] array; // 任务列表
// 线程工作的ForkJoinPool final ForkJoinPool pool; // the pool this thread works in // 工作窃取队列 final ForkJoinPool.WorkQueue workQueue; // work-stealing mechanics
publicabstractclassRecursiveTask<V> extendsForkJoinTask<V> { privatestaticfinallong serialVersionUID = 5232453952276485270L; /** * The result of the computation. */ V result; /** * The main computation performed by this task. * @return the result of the computation */ protectedabstract V compute(); publicfinal V getRawResult(){ return result; } protectedfinalvoidsetRawResult(V value){ result = value; } /** * Implements execution conventions for RecursiveTask. */ protectedfinalbooleanexec(){ result = compute(); returntrue; } }
publicfinal Throwable getException(){ int s = status & DONE_MASK; return ((s >= NORMAL) ? null : (s == CANCELLED) ? new CancellationException() : getThrowableException()); }
@Test public void testSetParallelMutli() throws ExecutionException, InterruptedException { int[] threadCountArr = {2, 4, 6}; List<Integer> para = new ArrayList<>(); for (int i = 0; i < 7; i++) { para.add(i);
} for (int threadCount : threadCountArr) { new ForkJoinPool(threadCount).submit(() -> {//多线程任务 System.out.println(Thread.currentThread().getName()); }).get(); } }
/** * 拆分任务到JobSender * {@link Stream#reduce(Object, BiFunction, BinaryOperator)} * <p> * reduce.Object --> 初始值,只是为了来初始化参数类型 * reduce.BiFunction.apply(T t, U u) --> t表示当前值, u表示当前操作对象 * reduce.BinaryOperator(T t, U u) --> t=u=初始值类型,用来合并结果的 * </p> */ int total = list.parallelStream().filter(op -> lockAdaptor.lock(op.getId(), LockAdaptor.DEFAULT_TIMEOUT)).reduce(0, (cur, channel) -> { // 构建发送器 + 并处理 int ava; try { ava = (jobSenderFactory.getSender(channel).process().dealSuccess() ? 1 : 0); } finally { // 解锁 lockAdaptor.unlock(channel.getId()); } return cur + ava; }, (a, b) -> a + b); logger.info("[消息补偿任务-并行执行]结束,本次预处理总数为[{}], 成功总数[{}], 未成功总数[{}]", list.size(), total, list.size() - total);
1、测试一、8核机器,每个任务均耗时2秒,一共16个任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
@Test public void testSetParallelMutli2() throws ExecutionException, InterruptedException { List<Integer> para = new ArrayList<>(); for (int i = 0; i < 16; i++) { para.add(i);
@Test public void testSetParallelMutli2() throws ExecutionException, InterruptedException { List<Integer> para = new ArrayList<>(); for (int i = 0; i < 16; i++) { para.add(i);
java.lang.ArrayIndexOutOfBoundsException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) ……
Caused by: java.lang.ArrayIndexOutOfBoundsException: 15 at java.util.ArrayList.add(ArrayList.java:463) at com.github.bjlhx15.common.thread.juc.collection.jdk8stream.TStreamTest.lambda$testExec$6(TStreamTest.java:118) at java.util.stream.ForEachOps$ForEachOp$OfRef.accept(ForEachOps.java:184) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1382) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.ForEachOps$ForEachTask.compute(ForEachOps.java:291)
我们就从数组和链表两种数据结构来看,基于数组线程安全的队列,比较典型的是ArrayBlockingQueue,它主要通过加锁的方式来保证线程安全;基于链表的线程安全队列分成LinkedBlockingQueue和ConcurrentLinkedQueue两大类,前者也通过锁的方式来实现线程安全,而后者以及上面表格中的LinkedTransferQueue都是通过原子变量compare and swap(以下简称“CAS”)这种不加锁的方式来实现的。
/** * Atomically adds the given value to the current value. * * @param delta the value to add * @return the previous value */ public final int getAndAdd(int delta) { for (;;) { int current = get(); int next = current + delta; if (compareAndSet(current, next)) return current; } } /** * Atomically sets the value to the given updated value * if the current value {@code ==} the expected value. * * @param expect the expected value * @param update the new value * @return true if successful. False return indicates that * the actual value was not equal to the expected value. */ public final boolean compareAndSet(int expect, int update) { return unsafe.compareAndSwapInt(this, valueOffset, expect, update); }
package com.meituan.FalseSharing; public class FalseSharing implements Runnable{ public final static long ITERATIONS = 500L * 1000L * 100L; private int arrayIndex = 0; private static ValuePadding[] longs; public FalseSharing(final int arrayIndex) { this.arrayIndex = arrayIndex; } public static void main(final String[] args) throws Exception { for(int i=1;i<10;i++){ System.gc(); final long start = System.currentTimeMillis(); runTest(i); System.out.println("Thread num "+i+" duration = " + (System.currentTimeMillis() - start)); } } private static void runTest(int NUM_THREADS) throws InterruptedException { Thread[] threads = new Thread[NUM_THREADS]; longs = new ValuePadding[NUM_THREADS]; for (int i = 0; i < longs.length; i++) { longs[i] = new ValuePadding(); } for (int i = 0; i < threads.length; i++) { threads[i] = new Thread(new FalseSharing(i)); } for (Thread t : threads) { t.start(); } for (Thread t : threads) { t.join(); } } public void run() { long i = ITERATIONS + 1; while (0 != --i) { longs[arrayIndex].value = 0L; } } public final static class ValuePadding { protected long p1, p2, p3, p4, p5, p6, p7; protected volatile long value = 0L; protected long p9, p10, p11, p12, p13, p14; protected long p15; } public final static class ValueNoPadding { // protected long p1, p2, p3, p4, p5, p6, p7; protected volatile long value = 0L; // protected long p9, p10, p11, p12, p13, p14, p15; } }
public long tryNext(int n) throws InsufficientCapacityException { if (n < 1) { throw new IllegalArgumentException("n must be > 0"); } long current; long next; do { current = cursor.get(); next = current + n; if (!hasAvailableCapacity(gatingSequences, n, current)) { throw InsufficientCapacityException.INSTANCE; } } while (!cursor.compareAndSet(current, next)); return next; }
public class DisruptorMain { public static void main(String[] args) throws Exception { // 队列中的元素 class Element {
private int value;
public int get(){ return value; }
public void set(int value){ this.value= value; }
}
// 生产者的线程工厂 ThreadFactory threadFactory = new ThreadFactory(){ @Override public Thread newThread(Runnable r) { return new Thread(r, "simpleThread"); } };
// RingBuffer生产工厂,初始化RingBuffer的时候使用 EventFactory<Element> factory = new EventFactory<Element>() { @Override public Element newInstance() { return new Element(); } };
// 处理Event的handler EventHandler<Element> handler = new EventHandler<Element>(){ @Override public void onEvent(Element element, long sequence, boolean endOfBatch) { System.out.println("Element: " + element.get()); } };
// 阻塞策略 BlockingWaitStrategy strategy = new BlockingWaitStrategy();
Valid values: Block, Timeout, Sleep, Yield. Block is a strategy that uses a lock and condition variable for the I/O thread waiting for log events. Block can be used when throughput and low-latency are not as important as CPU resource. Recommended for resource constrained/virtualised environments. Timeout is a variation of the Block strategy that will periodically wake up from the lock condition await() call. This ensures that if a notification is missed somehow the consumer thread is not stuck but will recover with a small latency delay (default 10ms). Sleep is a strategy that initially spins, then uses a Thread.yield(), and eventually parks for the minimum number of nanos the OS and JVM will allow while the I/O thread is waiting for log events. Sleep is a good compromise between performance and CPU resource. This strategy has very low impact on the application thread, in exchange for some additional latency for actually getting the message logged. Yield is a strategy that uses a Thread.yield() for waiting for log events after an initially spinning. Yield is a good compromise between performance and CPU resource, but may use more CPU than Sleep in order to get the message logged to disk sooner.
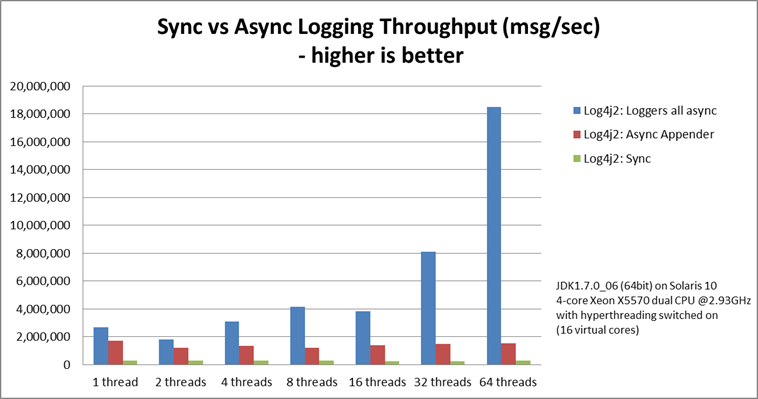
性能差异
loggers all async采用的是Disruptor,而Async Appender采用的是ArrayBlockingQueue队列。
由图可见,单线程情况下,loggers all async与Async Appender吞吐量相差不大,但是在64个线程的时候,loggers all async的吞吐量比Async Appender增加了12倍,是Sync模式的68倍。
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
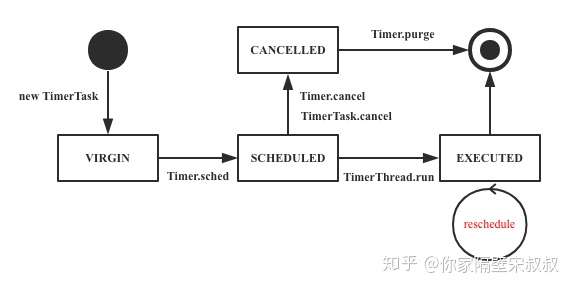
public abstract class TimerTask implements Runnable { final Object lock = new Object();
//任务状态 int state = VIRGIN; static final int VIRGIN = 0; static final int SCHEDULED = 1; static final int EXECUTED = 2; static final int CANCELLED = 3; //下次执行时间 long nextExecutionTime; //调度至执行间隔时间 long period = 0; }
/** 定时调度 */ public void schedule(TimerTask task, Date time) {
//从指定时刻出开始调度 sched(task, time.getTime(), 0); }
/** 延时周期性调度 */ public void schedule(TimerTask task, long delay, long period) { if (delay < 0) throw new IllegalArgumentException("Negative delay."); if (period <= 0) throw new IllegalArgumentException("Non-positive period."); sched(task, System.currentTimeMillis()+delay, -period); }
/** 定时周期性调度 */ public void schedule(TimerTask task, Date firstTime, long period) { if (period <= 0) throw new IllegalArgumentException("Non-positive period."); sched(task, firstTime.getTime(), -period); }
Timer.schedule()侧重period时间的一致性,保证执行任务的间隔时间相同。
定频率调度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/** 延时周期性定速调度 */ public void scheduleAtFixedRate(TimerTask task, long delay, long period) { if (delay < 0) throw new IllegalArgumentException("Negative delay."); if (period <= 0) throw new IllegalArgumentException("Non-positive period."); sched(task, System.currentTimeMillis()+delay, period); }
/** 定时周期性定速调度 */ public void scheduleAtFixedRate(TimerTask task, Date firstTime, long period) { if (period <= 0) throw new IllegalArgumentException("Non-positive period."); sched(task, firstTime.getTime(), period); }
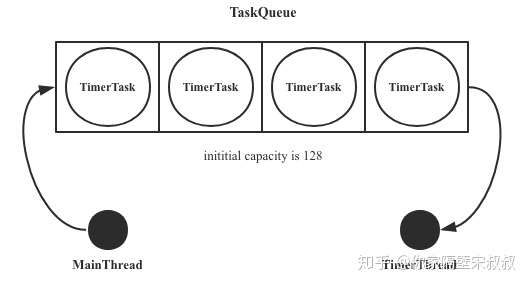
private void sched(TimerTask task, long time, long period) { if (time < 0) throw new IllegalArgumentException("Illegal execution time."); if (Math.abs(period) > (Long.MAX_VALUE >> 1)) period >>= 1;
synchronized(queue) {
//保证定时器未被取消 if (!thread.newTasksMayBeScheduled) { throw new IllegalStateException("Timer already cancelled."); }
synchronized(task.lock) { //保证任务最初处于未使用状态 if (task.state != TimerTask.VIRGIN) { throw new IllegalStateException( "Task already scheduled or cancelled"); }
public int purge() { //从队列中移除的任务数 int result = 0; synchronized(queue) { for (int i = queue.size(); i > 0; i--) { //从队列中移除取消状态任务 if (queue.get(i).state == TimerTask.CANCELLED) { queue.quickRemove(i); result++; } } //如果仍有非取消任务,队列重新堆化 if (result != 0) queue.heapify(); } return result; }
若请求成功返回200,包体格式查看具体接口,对响应包体使用连连支付的RSA私钥用SHA256WithRSA做签名并用Base64编码,生成的签名字符串放入HTTP包头xxx-Signature标签中,格式为xxx-Signature: t = response_epoch, v = signature。 其中:
MySQL 是一种关系型数据库,在Java企业级开发中非常常用,因为 MySQL 是开源免费的,并且方便扩展。阿里巴巴数据库系统也大量用到了 MySQL,因此它的稳定性是有保障的。MySQL是开放源代码的,因此任何人都可以在 GPL(General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL的默认端口号是3306。
存储引擎
一些常用命令
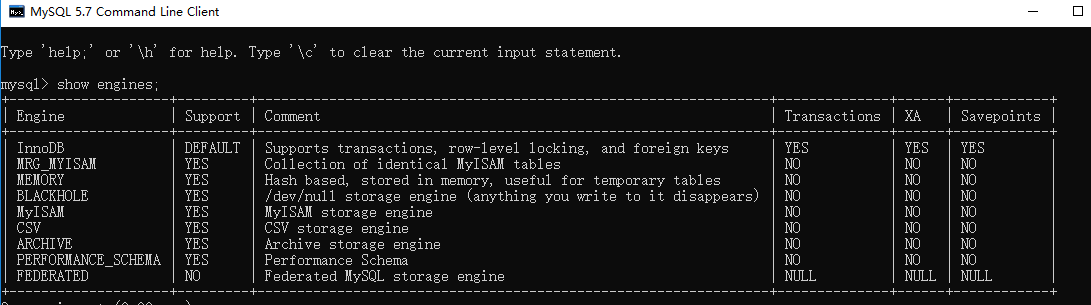
查看MySQL提供的所有存储引擎
1
mysql> show engines;
从上图我们可以查看出 MySQL 当前默认的存储引擎是InnoDB,并且在5.7版本所有的存储引擎中只有 InnoDB 是事务性存储引擎,也就是说只有 InnoDB 支持事务。
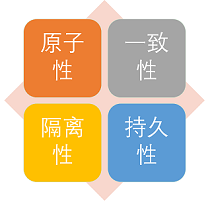
丢失修改(Lost to modify): 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。